
Si has oído hablar alguna vez de apps como LM Studio u Ollama, es posible que hayas pasado por alto Jan AI. Al igual que las otras dos opciones, esta app convierte la IA en un programa más dentro de nuestro PC. Como puede ser un editor de texto o cualquier navegador.
En lugar de utilizar un chatbot en una web como la de ChatGPT, solo tenemos que descargar Jan, que está disponible para Windows, macOS o Linux. Luego elegimos un modelo de IA y comenzamos a chatear con él al más puro estilo «ChatGPT». Pero la principal diferencia es también la razón de ser de Jan: está pensada para que todo funcione a nivel local, con total privacidad para el usuario.
Qué es Jan AI
Jan es una aplicación de chat con IA disponible para Windows, macOS y Linux que supone una alternativa gratuita perfecta a ChatGPT, y que además instalamos en nuestro propio ordenador. La premisa de su funcionamiento es muy sencilla: no dependeremos de los servicios ni servidores de OpenAI o Google. Solo descargamos los modelos de lenguaje en nuestro PC y hablamos con ellos desde una interfaz muy parecida a cualquier chatbot actual. Lo que quiere decir que podremos utilizar un servicio de IA incluso sin conexión a internet (como si lo quieres utilizar en un vuelo a Japón o Filipinas). Todas las conversaciones, archivos y datos quedan dentro de nuestro propio hardware.
Este proyecto es open source, con licencia Apache 2.0. Y todo su funcionamiento se apoya en una filosofía muy clara, dividida en 3 pilares:
- Abierto: el código está publicado en GitHub. Por lo que la comunidad puede revisarlo, proponer mejoras y crear extensiones.
- Privado: cuando eliges un modelo a ejecutar, toda la computación y los resultados se generan con nuestra CPU o GPU. Nada se envía a la nube, excepto si tú decides conectarte a cualquier proveedor en cloud.
- Todo es de tu propiedad: tú decides qué modelo utilizar, qué datos cargar y cuándo borrar todo.
Para los usuarios que hayan probado ChatGPT en el navegador, la principal diferencia es el lugar «donde vive» la IA. Con ChatGPT, todo vive en su servidor, y lo mismo ocurre con Gemini y Google o con Claude y Anthropic. Con Jan, nosotros descargamos la «inteligencia», para ejecutarla en nuestro PC. Por eso mismo decimos que puede seguir utilizando una IA dentro de un tren sin cobertura y que tus conversaciones no se suben a ningún servidor. Y por supuesto, eso también quiere decir que no pagamos por ninguna suscripción mensual ni por cantidad de mensajes enviados. El coste es básicamente el que hayas decidido desembolsar en tu hardware.
Para su funcionamiento, Jan se apoya en su propio motor, llamado Cortex. Este se encarga de ejecutar los modelos en nuestro PC y los expone a la propia app de chat. Y por encima de ese motor, está la interfaz de Jan, su «rostro», que puede recordarnos al de ChatGPT o análogo: lista de conversaciones, ventana de mensajes y botones para cambiar de modelo e incluso crear asistentes con instrucciones aparte.
Cómo funciona Jan AI
Aunque su razón de ser es su modo offline, en realidad la app también alberga modelos online que puedes combinar como tú quieras. Pero en todo momento tú puedes elegir qué tipo de modelo te interesa, dependiendo de la tarea o los recursos que tenga tu PC.
Para descargarlo, solo tienes que acceder a su web oficial, y seleccionar tu versión: Windows, macOS o Linux. Todas con las mismas prestaciones y gratuidad. En nuestro caso, vamos a descargar la versión de Windows. Y su funcionamiento no puede ser más sencillo. Una vez lo descargues y hagas clic sobre el archivo ejecutable, nos encontraremos con esta ventana:
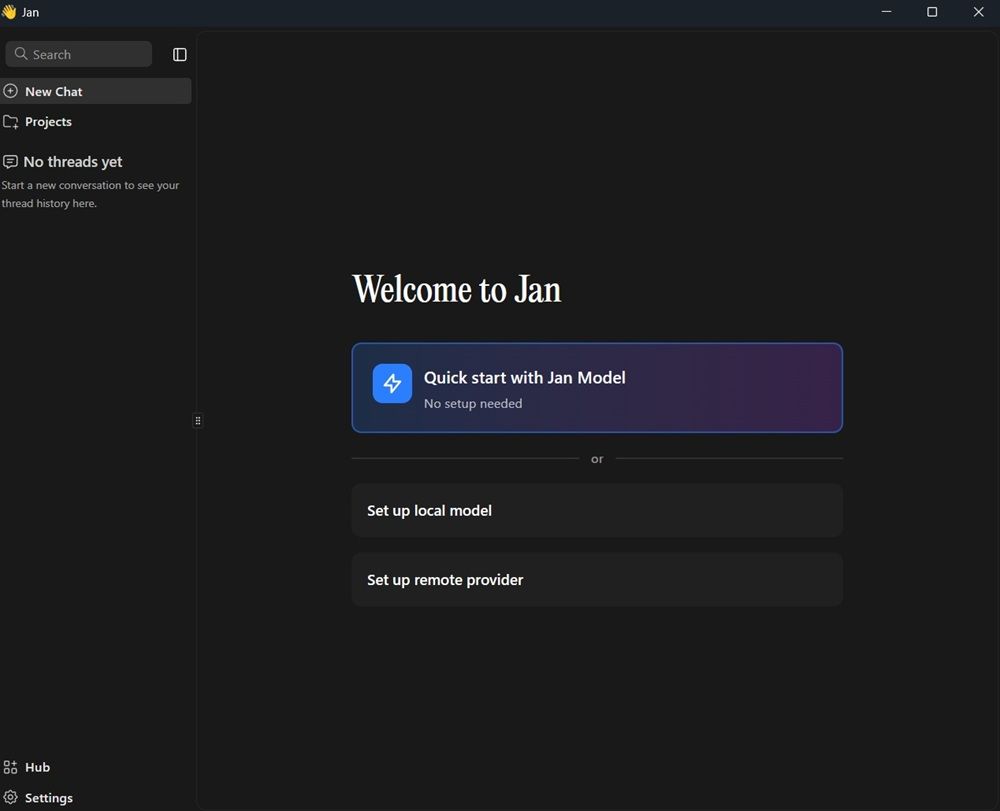
Como puedes ver, desde un primer momento nos encontramos con 3 opciones bien diferenciadas. Pero antes de proseguir, te adelantamos que el idioma español no está disponible en su interfaz, aunque sí puedes tener una conversación en castellano sin mayor problema con cualquiera de sus modelos.
Inicio rápido con el modelo propio de Jan
En primer lugar, nos encontramos la opción «Quick start with Jan Model«, resaltada en tonalidades moradas, y donde se nos indica que no es necesaria ninguna instalación. Aun así, al pulsar sobre él, comenzará a descargarse dicho modelo. Lo cual no se extiende más de un par de minutos. Aun así, es la forma más sencilla de comenzar a usar Jan sin que tengamos que tomar ninguna decisión importante. En lugar de obligarnos a buscar en varias listas, cuenta con su propio modelo preconfigurado.
Este «Jan Model» es un LLM generalista, entrenado para cubrir las tareas más básicas que se le piden a un asistente: redactar texto, resumir, reescribir, traducir, o responder preguntas de cultura general. Es equilibrado, pero no es el más potente del mundo. Aun así, suele ofrecer una buena calidad en su respuesta con un consumo muy razonable de recursos. Una vez que lo descargues, solo tienes que hacerle la primera pregunta para que comience a trabajar en ello:
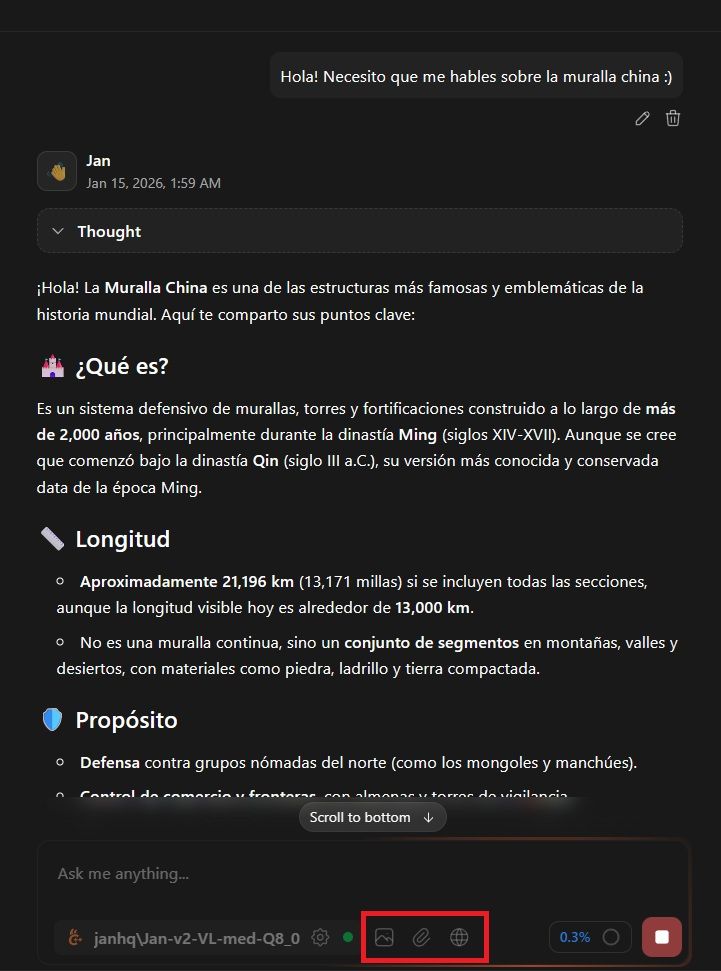
Como puedes ver en la captura, nos da una respuesta acorde a la sencilla solicitud que le hemos pedido mediante el prompt. Ahora bien, no podemos pasar por alto tampoco sus funciones rodeadas de rojo en la imagen, explicadas de izquierda a derecha:
- Visión: nos permite cargar una imagen para que la analice y pueda trabajar con ella. Podemos hacerle preguntas al respecto o pedirle información importante sobre la misma.
- Adjuntar documentos: de igual manera, podemos adjuntar documentos PDF o Word para que la propia IA pueda trabajar con ellos: analizarlos, pedir consejos de estilo, fallos ortográficos, etc.
- Búsqueda web: al activarla, permitiremos que el propio modelo haga uso de búsqueda en internet para responder a nuestras preguntas. Obviamente, totalmente opcional, al igual que las otras dos opciones.
Esta es la manera más sencilla de utilizar Jan, pero ni mucho menos la única. Por lo que vamos a pasar a elegir entre modelos offline especializados u online.
Modelos locales en Jan
Pero el punto más fuerte y positivo de Jan son los modelos disponibles para su descarga y uso en nuestro propio PC. Son esos «cerebros» que descargamos y con los que podemos chatear incluso aunque no tengamos conexión a internet. Para descargar y gestionar los distintos modelos locales que tenemos a nuestra disposición, el camino más sencillo es la pestaña «Hub», que podemos encontrar abajo a la izquierda de la interfaz:
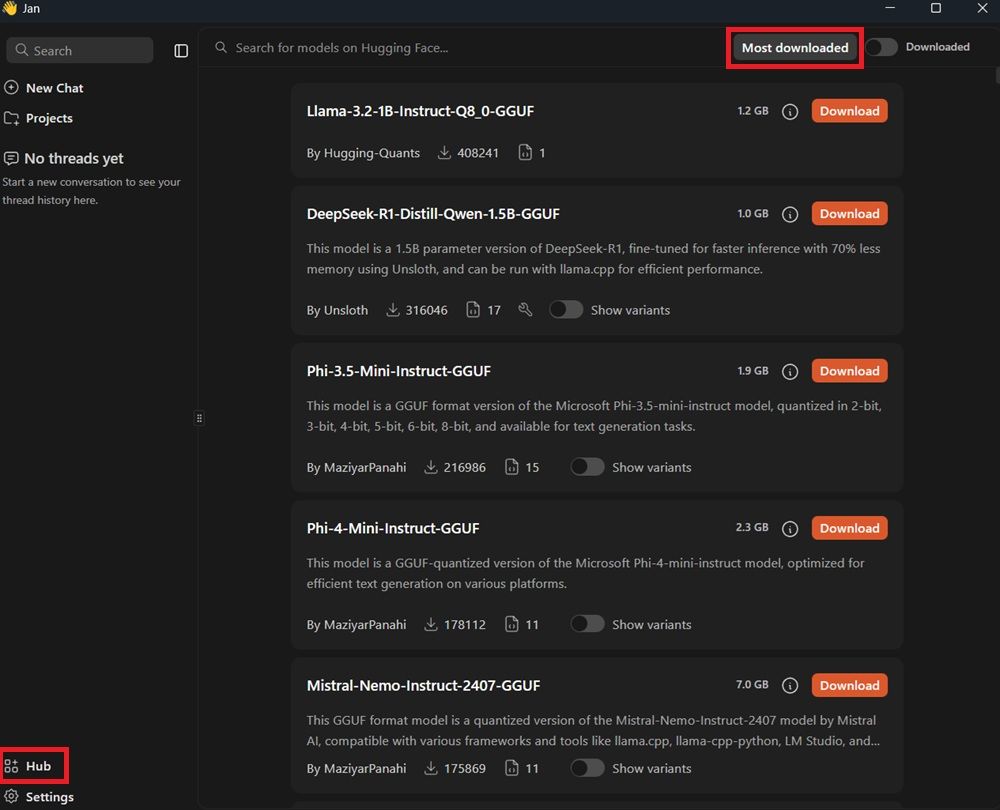
Una vez que pulses sobre la opción de «Hub», se desplegará un listado de modelos recomendados. Pero tal y como puedes ver en la parte superior, encontrarás la opción «Most downloaded». También puedes establecer ese filtro con «Newest». En cualquier caso, es una buena forma de orientarse, en caso de que no sepas por cuál empezar. Desde la opción «Most downloaded», tiende a colocar primero los modelos más equilibrados en cuanto a calidad y rendimiento.
Como ves, cada modelo aparece con su propia tarjeta, donde se muestra la información clave de cada uno y una pequeña descripción. Aparecen factores como el nombre completo, tamaño en GB, autor, número de descargas, etc. Para descargar cualquiera de ellos, solo tienes que pulsar la opción «Download» que aparece sobre el cuadro naranja.
Ten en cuenta que todo lo que ves en pantalla son modelos locales en formato GGUF. Es decir, que están pensados para ejecutarse offline dentro de Jan. No son modelos en la nube. En cuanto pulsas Download, el archivo comienza a guardarse en tu disco, y una vez terminado el proceso, puedes usarlo sin necesidad de internet.
Principales modelos descargables
Con el filtro «Most downloaded» activo, Jan nos enseña los principales modelos que ha descargado la comunidad. Que sirven muy bien como referencia para lo que queremos utilizar Jan.
Llama-3.2-Instruct-Q8_0-GGUF
Una versión muy ligera de la familia Llama 3.2, con alrededor de 1.000 millones de parámetros y afinada para instrucciones concretas. Su punto fuerte es que consume poca RAM y arranca rápido, lo que la hace muy compatible con ordenadores no tan potentes. Además, responde con solvencia a las preguntas sencillas, resúmenes breves y explicaciones básicas. Pero también notamos una gran diferencia frente a modelos grandes cuando pedimos razonamientos complejos, textos muy largos o código complejo. Ahí sí que se queda corto frente a otros.
DeepSeek-R1-Distill-Qwen-1.5B-GGUF
Una versión ligera de DeepSeek-R1, basada en Qwen de 1,5B de parámetros. Está optimizada para ofrecer un buen rendimiento mientras hace uso de menos memoria. Por lo que ofrece un buen equilibrio entre calidad y ligereza, con un tamaño parecido al de Llama 3.2. Sin embargo, es cierto que rinde mejor en razonamiento y explicaciones más largas, e incluso llega a mantener tiempos de respuesta muy razonables aunque la GPU de nuestro PC no sea muy potente.
Uno de los candidatos más interesantes a descargar si quieres algo un poco más capaz que el anterior, aunque sigas limitado por la capacidad de tu propia memoria RAM.
Phi-3.5-Mini-Instruct-GGUF
Uno de los modelos más pequeños de Microsoft, y que mejor reputación tiene a la hora de desempeñar tareas generales. A pesar de ser «mini», ofrece muy buena calidad en cuanto a conversación, escritura creativa y explicación de conceptos. Y con un peso de 1,9 GB es muy asequible para ordenadores con 16 GB de RAM. Aun así, notarás más consumo que con los dos modelos anteriores.
Phi-4-Mini-Instruct-GGUF
Phi-4 Mini es una evolución de 3.5, dentro de la misma familia. Es más grande y más exigente con nuestro PC, pero también es más coherente en contextos más largos. De hecho, mejora la comprensión con diálogos más extensos y con tareas de razonamiento. Pero aun así, conviene que tengamos más de 16 GB de RAM para que pueda moverse y no consuma recursos excesivos del sistema. Lo que quiere decir que, si nuestro PC puede ejecutarlo, es un salto de calidad sobre Phi-3.5 Mini.
Mistral-Nemo-Instruct-2407-GGUF
Este modelo supera de largo a los anteriores. De hecho, es una versión cuantizada del modelo Mistral Nemo Instruct, y ya es bastante más pesada, llegando a ocupar 7 GB de peso. Esto quiere decir que exige mucha más memoria (32 GB de RAM), y lo ideal es que puedas ejecutarlo con una GPU dedicada. Pero este precio tiene una mejoría muy clara: mejoras sustanciales en tareas de razonamiento, programación y manejo de contexto largo. Puede ser el primer modelo que se acerca a ofrecer una sensación de modelo de gama alta, aunque obviamente, todavía queda lejos de las últimas versiones de GPT y Gemini.
Modelos online en Jan
En Jan, los modelos online son la otra mitad de toda esta ecuación. A diferencia de los modelos que acabamos de explicar en el apartado anterior, estos sí que residen en servidores de empresas como OpenAI, Anthropic, Mistral o Google. Y su uso sí depende totalmente de internet. Y desde Jan, podemos elegir qué «cerebro en la nube» podemos utilizar.
Pero antes de proseguir, hemos de tener en cuenta que estos modelos online se ofrecer como servicio de pago. Es decir, mediante las API de cada distribuidor por separado. En primer lugar, debemos ir a la sección de «Settings», donde se nos mostrará el siguiente menú:
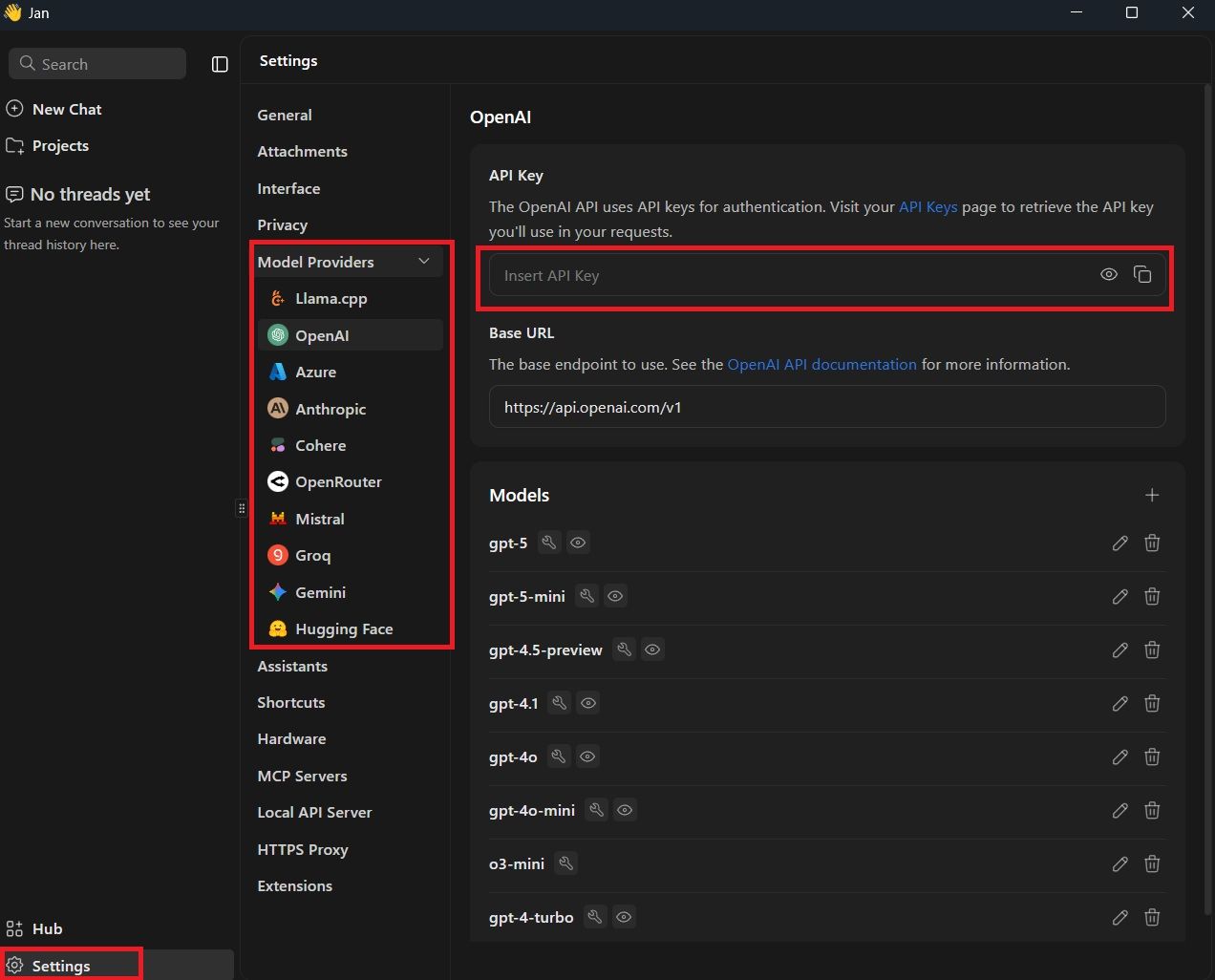
Cuando pulsemos sobre «Settings», se nos desplegará la columna izquierda, donde encontramos: General, Attachments, Interfaz, Privacy y, justo la que nos interesa, Model Providers. Al desplegar esta pestaña, encontrarás una serie de proveedores que puede que conozcas: OpenAI, Azure, Anthropic, Mistral, Gemini…
Al pulsar sobre una opción en particular, nos aparecerá un cuadro de configuración, donde podremos distinguir:
- El cuadro de texto dedicado a insetar la key API.
- La URL base para utilizar el modelo (viene por defecto, no es necesario modificarlo)
- Los distintos modelos que podemos utilizar en caso de optar por API. En caso de los modelos de OpenAI -en la imagen-, disponemos de gpt-5, gpt-5-mini, gpt-4.1, gpt-4o, etc.
La parte más importante de este método es que consigamos la API key del proveedor que queramos. En el caso de OpenAI, para utilizar sus distintos modelos de GPT, solo tienes que entrar en su web oficial para crear claves de API. Una vez dentro, te encontrarás con estas opciones:
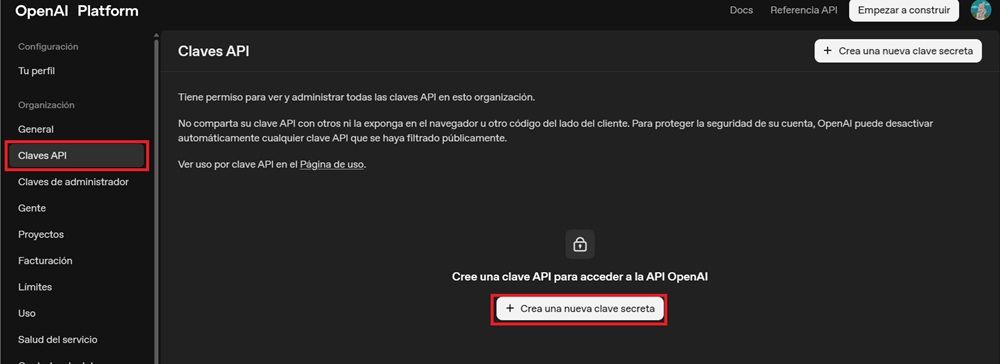
Desde la columna de la izquierda, encontrarás claramente visible la opción de «Claves API» o «API Keys», dependiendo del idioma. Por lo que luego, solo tienes que pulsar en la opción que aparece en blanco en el centro de la pantalla: «Crear una nueva clave secreta». Luego solo tenemos que poner un nombre y descripción y tendremos que copiar la clave en Jan, justo en la parte de «Insert API Key» que hemos explicado arriba.
A partir de ahí, solo tienes que seleccionar uno de los modelos disponibles de OpenAI en Jan y comenzar un nuevo chat. Pero recuerda que siempre será bajo la propiedad de los servidores de la compañía.
¿Hay que pagar por utilizar estos modelos?
Sí, casi siempre. Los proveedores de IA suelen funcionar por tarifas por uso. De hecho, lo lógico es que se cobre una cantidad por cada millón de tokens, sean generados o procesados. Pero en la práctica se traduce en unos céntimos por cada respuesta, dependiendo del modelo.
Jan de por sí no añade ningún tipo de recargo. La app actúa como un mero cliente. Pero sí pagas a OpenAI, Anthropic, Mistral, etc. Por lo tanto, solo es recomendable que utilices estos modelos online si necesitas prácticamente una calidad excepcional: razonamiento profundo, tareas de programación complejas o generación de código dentro de varios archivos. Para el resto de opciones, es mejor recurrir a modelos locales para las tareas diarias. Si vas a tomar notas, resumir documentos o escribir borradores, te basta con los modelos locales de Jan.


