
La evolución de la IA ha provocado que existan herramientas cuyo lanzamiento era cuestión de tiempo. Y ahora, los chatbots han llegado a los escritorios de Windows y otros sistemas operativos. En esa línea, ha llegado el momento de que echarle un vistazo a Ollama. Una app que permite que cualquier usuario ejecute modelos avanzados de IA directamente desde su PC. Lejos de cualquier nube o servidor externo.
Y es que el despliegue de los distintos modelos de lenguaje ha puesto en jaque un aspecto muy valorado por los usuarios: la privacidad y el control de los datos por parte de las grandes empresas. Precisamente en este contexto, Ollama se ha posicionado como una herramienta perfecta para cualquier usuario que busque una independencia total para sus proyectos. Gran parte de culpa de sus facilidades se las debemos a su sencillez tanto en la instalación como su uso.
De hecho, no es necesario tener conocimientos en Python ni gestionar complejas dependencias. Basta con que descarguemos la propia aplicación y comencemos a interactuar con los modelos más punteros de procesamiento de lenguaje natural, generación de texto y análisis.
Por ello, en este artículo vamos a explicar paso a paso cómo aprovechar todo el potencial de Ollama desde Windows, desde su descarga hasta su configuración inicial. Así como los modelos que se pueden ejecutar en el programa.
Qué es Ollama y sus ventajas
Ollama es una plataforma de IA local que ha cambiado de manera directa la manera en que los usuarios acceden y controlan modelos de lenguaje de última generación. Gracias a su uso, podemos ejecutar estos modelos en nuestro propio equipo. Es decir, que a diferencia de servicios como ChatGPT, Gemini o Claude, que requieren conexión directa a internet para utilizar su nube, Ollama permite ejecutar modelos directamente desde nuestro PC.
Por lo tanto, es un salto muy importante de cara a la privacidad de nuestros datos, sin contar con la gran ventaja que supone no necesitar conexión a internet y aun así disponer de las funciones de IA.
Además, nos encontramos ante un programa de uso gratuito, sin ningún tipo de cuotas mensuales ni restricciones comerciales. Por lo que estamos ante una verdadera oportunidad para aquellos que quieran democratizar el uso de la IA. Por otro lado, esta herramienta también destaca por su accesibilidad. Si bien en su origen estaba más enfocada en usuarios avanzados, hoy en día ya cualquier usuario con un mínimo de conocimiento puede instalar Ollama en Windows y tener su IA en cuestión de minutos.
Entre los modelos disponibles que podemos encontrar en Ollama, aunque los expandiremos más adelante, encontraremos Llama 3, Mistral, Gemma, y Phi-3. Todos perfectamente optimizados para funcionar a nivel local. Y con requerimientos tan asequibles como 8 GB de RAM y un procesador medio. Además, Ollama también es compatible con integracones y automatizaciones. Lo que nos brinda la posibilidad de utilizarlo en trabajos profesionales o incluso en apps personales.
Cómo descargar Ollama en Windows
Instalar Ollama en Windows es un proceso sencillo y apto para prácticamente cualquier usuario. El equipo de Ollama ha desarrollado un instalador gráfico que elimina la necesidad de utilizar comandos y configuraciones más complejas. Pero empecemos por el principio.
Todo empieza al acceder a la web oficial de descargas de Ollama. El único sitio seguro y legítimo a la hora de obtener los archivos necesarios. Desde ella, solo tenemos que descargar el archivo «OllamaSetup.exe» que encontrarás, en el caso de nuestra guía, para Windows. Lo harás desde el cuadro «Download for Windows. Requiere que bien tengamos Windows 10 o Windows 11. Ten en cuenta que el archivo tiene un peso de 1,1 GB.
Eso sí, antes de ejecutar su instalador, deberás verificar que tu PC cumple, al menos, con los requisitos básicos:
- Como hemos dicho, sistema operativo de Windows 10 u 11.
- 8 GB de capacidad de memoria RAM.
- CPU x86 con, al menos, cuatro núcleos. Por ejemplo, Intel Core i5/i7 de cuarta generación o AMD Ryzen 3/5/7.
- Opcionalmente, una GPU dedicada de NVIDIA o AMD mejora el rendimiento. Aun así, no es imprescindible para los modelos de IA más ligeros.
Primeros pasos en Ollama
Una vez que hayas descargado el archivo «OllamaSetup.exe», pulsa sobre el archivo y sigue los pasos del asistente. El proceso es similar al de cualquier otra app al uso, por lo que no requiere de ningún tipo de advertencia especial. En cuanto haya finalizado, se abrirá directamente su interfaz por primera vez:
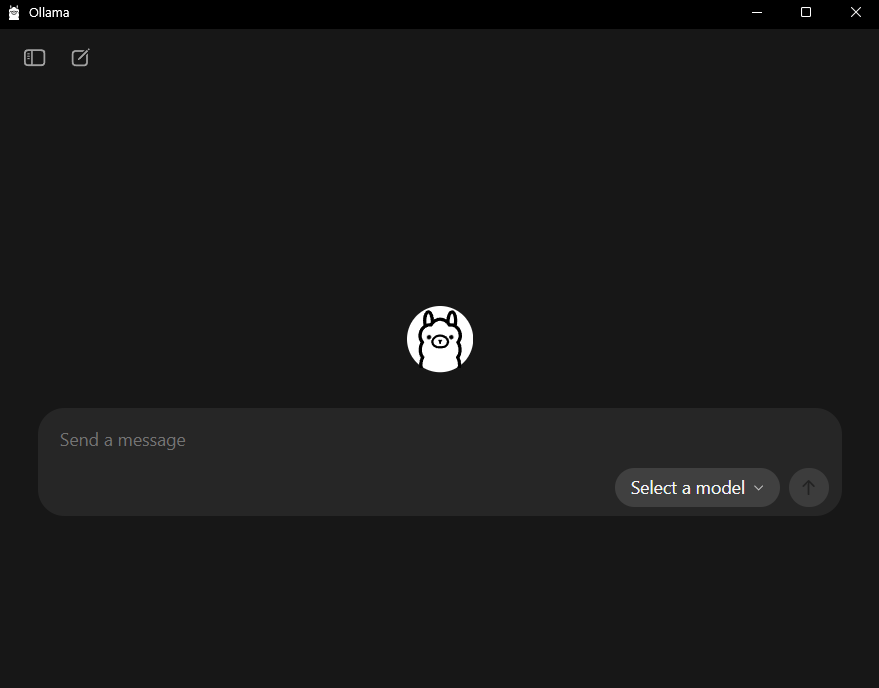
En este momento, encontraremos 3 opciones principales que saltan a la vista.
La primera de ellas, ubicada en la esquina izquierda superior, con forma de pantalla con menú lateral, nos dará paso a «nuevo chat» y a «opciones». Es aquí donde nos interesa ir en este momento. Una vez dentro de opciones, encontraremos este menú:
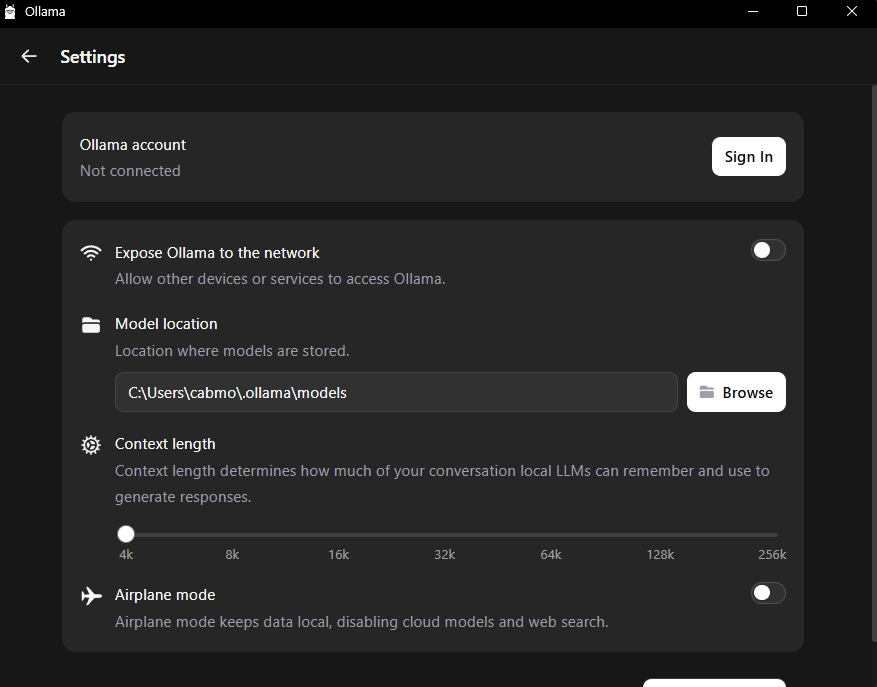
Tal y como puedes ver, tienes la posibilidad de ingresar tu cuenta de Ollama para contar con funciones online. Junto a ello, también puedes conectarte a la red mediante un interruptor. Aunque lo más importante aquí son los dos siguientes factores:
- La ubicación de los modelos. Que será la carpeta donde se guarden los modelos que descargaremos y utilizaremos.
- Contexto de lenguaje. Puedes configurarlo desde 4.000 tokens hasta 256.ooo. Aun así, has de tener en cuenta que cuanto más tokens configures, mayor uso hará de tu RAM. Por lo que lo ideal es que para equipos básicos lo configures entre 4K y 8K tokens. En equipos medios, con 16 de RAM, puedes configurarlo entre 16 y 32k tokens. Y en equipos avanzados, con 32 GB de RAM o más, puedes estirarlo hasta 64, 128 o incluso al máximo.
Volviendo al menú principal de Ollama, encontraremos los dos iconos restantes que nos serán de importancia. Por un lado, tenemos el símbolo del cuadrado atravesado por un lápiz, que es el selector de nuevo chat. Y la última de las opciones, la más importante de todas y que aparece en el cuadro de texto del chatbot, es el selector de modelos de IA.
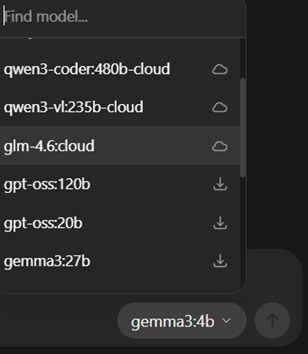
Este selector de modelos es la base sobre la que vamos a realizar todo nuestro trabajo en la interfaz de Ollama.
Modelos de IA disponibles para Ollama
Desde el selector de modelos, encontraremos un listado dividido en dos claras secciones. Por una parte, tenemos los modelos que Ollama nos da la opción de utilizar con funcionamiento en la nube (en la foto, aquellos modelos con el símbolo de la nube, y los modelos descargables para utilizar de manera local, sin necesidad de ningún tipo de conexión a internet. Así que vamos a desgranarlos basándonos en esta clasificación.
Modelos en la nube
gpt-oss120b
Un modelo de código abierto que se inspira en la arquitectura de GPT-4, pero disponible para tareas de contexto largo con una buena precisión. Este modelo es el adecuado para aquellos usuarios que pretenden buenas capacidades de resumen, generación creativa y un razonamiento avanzado sólido. Pero su verdadero punto fuerte es que no requiere de mucha RAM para funcionar.
deepseek-v3.1:67b
Este modelo es el de mayor contexto disponible en Ollama. Tiene capacidad para manejar hasta 256.000 tokens de manera sencilla y razonar sobre grandes volúmenes deinformación. Por lo que es la opción perfecta para consultas más técnicas y trabajos extensos de investigación.
qwen3-coder:480b
Esta versión de Qwen3 está pensada para las tareas de programación y la generación de código. Gracias a él, se nos ayuda a crear, depurar y explicar scripts complejos en varios lenguajes. Por lo que puede ser la opción favorita para los desarrolladores que quieren aprovechar la potencia en la nube para trabajar con bases de datos, proyectos webs o con automatizaciones
glm-4.6
Este modelo en la nube está orientado al procesamiento multilingüe con una buena base de razonamiento profundo. Por lo que es perfecto para quienes tienen proyectos en varios idiomas y quieren depurar el contenido y adaptarlo a diferentes lenguas.
Modelos locales
gpt-oss 120b
Versión de código abierto descargable oficial del modelo de ChatGPT. Nos proporciona un buen equilibrio ente velocidad y profundidad. Es la mejor opción para equipos que posean una buena cantidad de RAM (16 GB en adelante) y que quieren acercarse lo máximo posible al entorno de ChatGPT, pero con una privacidad absoluta. Nos permite generar texto, resúmenes y tareas creativas sin depender de la conexión a internet.
gemma3 27b
Uno de los modelos más potentes para instalar de manera local de la mano de Google. Recomendado para PCs con RAM de 32 gigas en adelante y tarjetas gráficas dedicadas. La clave de este modelo se encuentra en el razonamiento complejo y en el análisis crítico de documentos. Por lo que supera a muchos modelos ligeros en cuanto a tareas académicas o profesionales.
deepseek-r1:8b
El modelo perfecto para los usuarios que busquen el equilibrio entre rapidez y eficiencia. Ideal en equipos con menos potencia. Podemos encontrar respuestas ágiles y con buena capacidad de razonamiento. Lo que lo convierte en una buena opción para chats, motores de búsqueda internos y sistemas de automatización sencillos.
qwen 3.30b
El modelo local más sólido en generación y capacidad de razonamiento de Ollama. Es muy versátil para tareas más técnicas que requieran de un nivel de conversación avanzado, así como para el análisis de información de manera pormenorizada.
| Tamaño del modelo (cuantizado Q4) | Espacio en disco | RAM recomendada |
|---|---|---|
| ~3B | ~2 GB | 8 GB |
| 7B/8B | 4-5 GB | 16 GB |
| 30B | ~16 GB | 32 GB |
| 70B | ~40 GB | 32 GB+ |
Comienza a usar Ollama
Ahora que tienes los modelos más importantes a tu disposición, es hora de que comiences a descargar el sistema que más te convenza. Por lo que, es momento de volver a su interfaz principal y seleccionar uno de los modelos disponibles. Para esta prueba, hemos descargado gpt-oss:20b:
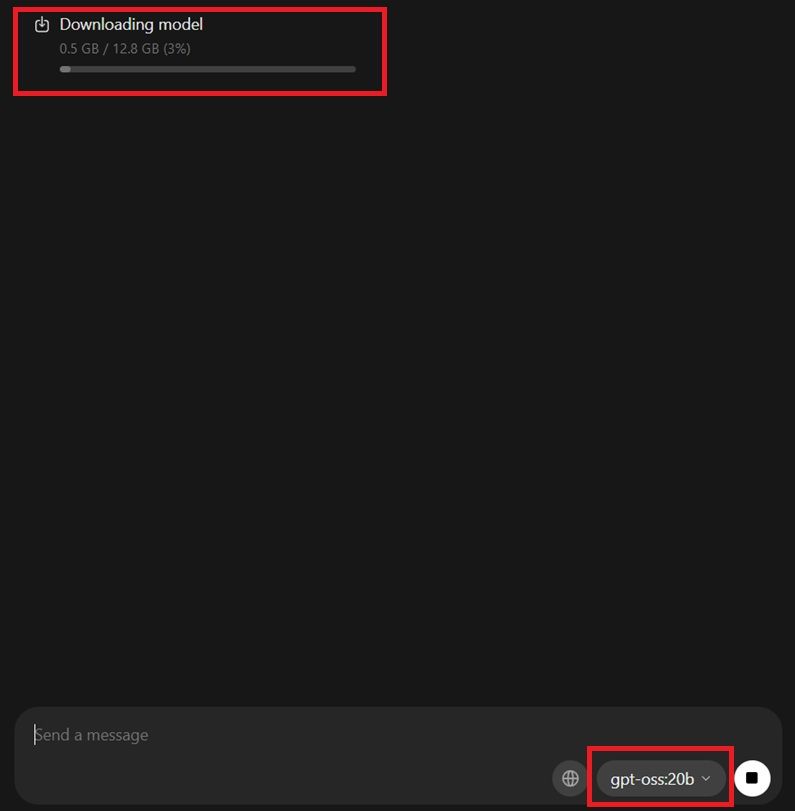
El proceso es bien sencillo, solo tienes que seleccionar el modelo de entre la lista y, a priori, no ocurrirá nada. Para que comience a descargarse, solo tenemos que escribir cualquier letra o palabra en el recuadro de texto. Cuando lo hagamos, comenzará a descargarse el modelo para que lo usemos para siempre de manera offline.
Solo tendremos que esperar a que finalice el proceso de descarga, tal y como se indica en la parte superior de la interfaz. Cuando lo haga, el propio modelo se configurará con los parámetros que hayamos facilitado en configuración y estará listo para utilizar. Solo tenemos que comenzar a hacerle cualquier pregunta que necesitemos y el propio modelo comenzará a pensar antes de arrojarnos una respuesta:
Por último, la IA detectará nuestro idioma sin mayor problema y nos dará la respuesta más adecuada atendiendo a su configuración de Tokens. De igual manera podemos dar instrucciones personalizadas para que se atenga a un número de palabras mínimo para sus respuestas o estructure la información en varios epígrafres separados:
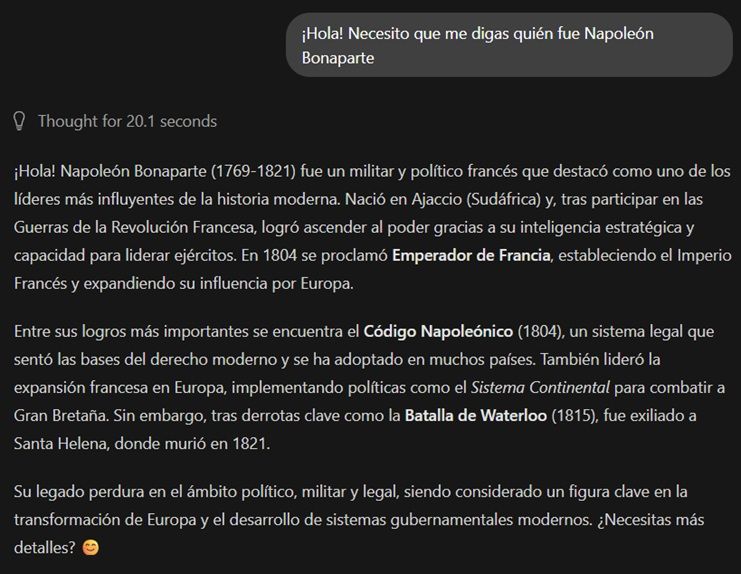
A la hora de responder, se nos indicará sobre el texto generado el tiempo necesario para generar dicha respuesta.
Aunque nosotros hemos utilizado el modelo gpt-oss:120b para descargar, recuerda que dispones de más modelos, incluso en versiones de nube, en caso de que no quieras utilizar el espacio de almacenamiento de tu PC. En el caso de que optemos por las versiones en nube de cualquiera de los ofrecidos, no será necesaria ninguna descarga. Directamente funcionará con que hagamos una pregunta al modelo y funcionará al más puro estilo ChatGPT, Gemini o Perplexity.
Como puedes ver, el potencial offline y también online de Ollama es prácticamente ilimitado, y puede ser nuestro asistente perfecto para la búsqueda, recopilación y creación de información en cualquier ámbito de nuestros proyectos.


