

Al igual que ha ocurrido con la Fiebre del oro, y otras grandes tendencias históricas que han marcado época. Ahora nos encontramos en la «Fiebre de la IA». Sin embargo, todavía, la mayoría de nosotros todavía estamos intentando adaptarnos a estos nuevos modelos que llegan para cambiarlo todo: ChatGPT, Claude, Gemini…
Pero no nos encontramos ante cajas fuertes de origen mágico, sino ante motores de ingeniería de vanguardia que tienen un funcionamiento. El mero hecho de entender ese funcionamiento nos permite trucarlo, ajustarlo o modular la potencia como necesitemos. Entender qué es un LLM (Large Language Model, o Gran Modelo de Lenguaje) no debería ser una mera curiosidad para informáticos, sino una alfabetización fundamental de cara al futuro.
En este artículo no te vamos a soltar una «biblia» sobre teoría académica. Queremos poner en práctica los conceptos más importantes de un Modelo de Lenguaje y cómo descifrar esos famosos códigos de «70B» o una «Temperatura de 0,8». Así que vamos con un manual de mecánica de la nueva era de la tecnología.
Un LLM es pura estadística
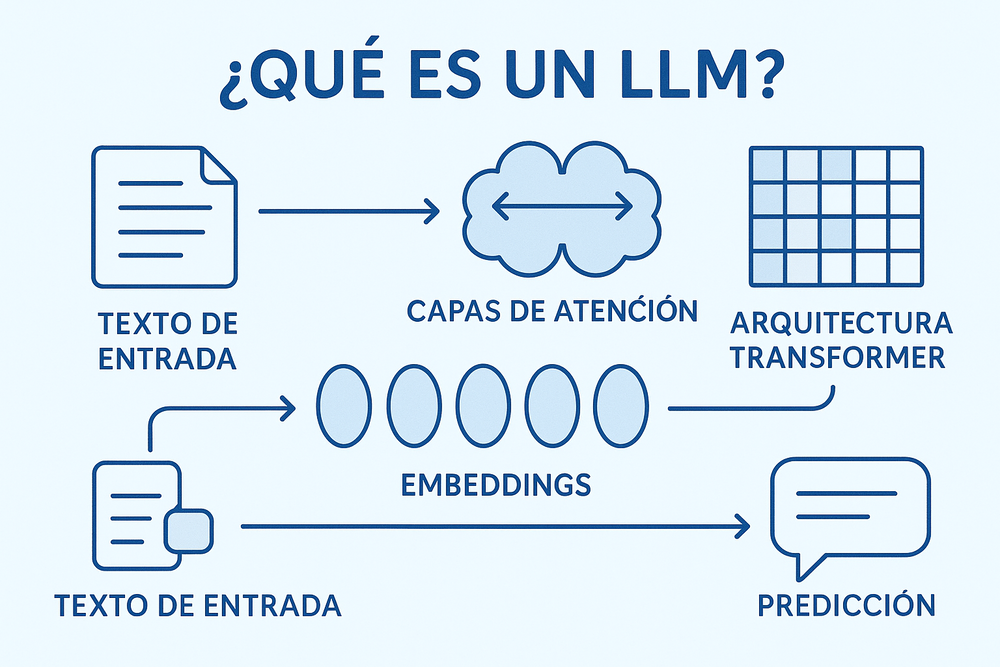
Lo primero que hemos de aclarar, desde un primer momento, es que un LLM no es una «enciclopedia». No sabe nada. No tiene consciencia, y desde luego, no cuenta con un cerebro escondido en ningún servidor. Podemos decir que básicamente, su única función vital es PREDECIR la siguiente palabra una y otra vez, y así, miles de millones de veces cada vez que tenemos una consulta.
Por ejemplo, cuando estamos escribiendo un mensaje con nuestro móvil, en muchas ocasiones aparece el teclado predictivo. Un LLM hace exactamente lo mismo, pero no se basa en las últimas tres letras o palabras que escribimos. En su lugar, lo hace con prácticamente todo el texto que existe en internet (de manera optimizada y comprimida). Si nosotros le preguntamos por la capital de Japón, el modelo no busca en una base de datos geográfica. Simplemente, calcula que, tras la secuencia de palabras que hemos escrito, la palabra «Tokio» tiene un 99,999999% de probabilidades de aparecer.
La base de un LLM: El Token
Seguramente, en cualquiera de nuestros artículos o en cualquier manual de IA de internet habréis leído ese término: Token.
Los modelos no leen letras ni palabras completas como lo hacen nuestros ojos. Sino que leen tokens. Un token puede ser una palabra corta, como «gato», o parte de una palabra («in-, ex-, des-…»). O incluso puede ser el símbolo del espacio. Existe un caso muy paradigmático que ponía de manifiesto este comportamiento, y era el de preguntarle a una IA cuántas «R» tiene la palabra «Strawberry». Lo normal es que respondieran 2, pero no porque no sepan contar. Sino porque para el modelo de lenguaje, strawberry consta de dos tokens indivisibles «straw + berry». El modelo solo «ve» el bloque entero, no las letras individuales. No puede contar las «R» porque no las ve separadas a menos que lo obliguemos a deletrear primero.
El motor: el Transformer
Todo este mecanismo funciona gracias a una arquitectura de software llamada «Transformer». Que, curiosamente, es la «T» de GPT. Esta fue inventada por Google en el año 2017, y su gran revolución fue introducir lo que llamamos el «mecanismo de atención». Antes, las IA leían frases de izquierda a derecha y normalmente olvidaban el principio antes de llegar al final. El Transformer puede «prestar atención» a todas las palabras de manera simultánea y es capaz de generar un contexto.
Por ejemplo, en la frase: «El banco estaba cerrado porque era fin de semana», este modelo es capaz de contextualizar que estamos hablando de una entidad bancaria, y no de un asiento en la calle
El glosario de la IA: parámetros, pesos y temperaturas
Siempre que entramos en una plataforma comercial de IA, o bien en cualquier repositorio para descargar un LLM (luego veremos los tipos de LLM disponibles y cómo hacerse con ellos), nos encontramos una serie de códigos que parecen de origen nuclear. En realidad, son mucho más sencillos de lo que te imaginas. Por lo que vamos a traducirlos fácilmente.
Parámetros (7B, 70B, 405B…)
Si nuestro cerebro consta de neuronas, los LLMs cuentan con parámetros. Es una medida aproximada de la «capacidad mental» del modelo. Pero obviamente, existen escalas con las que cuantificar esta capacidad:
- 7B – 9B: son modelos pequeños como pueden ser Llama 3 8B o Gemma 2 9B. Son ligeros y lo normal es que puedan ejecutarse en un PC doméstico. Pero mucho ojo, porque si le pedimos demasiado pueden «alucinar» (o predecir mal las palabras y hacer pasar por válida información que no lo es).
- 70B: modelos medianos, Como Llama 3 70B. El equilibrio entre potencia y utilidad. Tiene mayor potencia, pero requiere de tarjetas gráficas potentes o de alijarse en una nube. En esta ocasión, su razonamiento ya se acerca al de un nivel humano experto.
- 400B en adelante: son los modelos gigantes. GPT-5.2 O Gemini 3 Flash tienen un conocimiento enciclopédico gigantesco y una extraordinaria capacidad de razonamiento. Obviamente, es imposible de utilizar a nivel local en un hogar, por lo que requiere de centros de datos enormes y un servidor para surtir a todos sus usuarios.
Sin embargo, has de tener en cuenta que «más parámetros» no siempre significa «mejor respuesta». En este caso, lo que significa es que tiene más capacidad de razonar. Recuerda que hablamos de neuronas, no de nuestra «lengua».
Ventana de contexto
Es la memoria a corto plazo de un modelo. Si los parámetros es su inteligencia y capacidad de razonar, la ventana de contexto «cuántas páginas de un libro puede leer ahora mismo sin olvidar la primera». Esta característica tiene muchísima importancia a la hora de trabajar con nuestros propios documentos personales, pues conlleva que pueda leer una serie de apuntes o de documentos importantes en su total extensión.
Los primeros modelos de IA nacieron con 4.000 tokens de ventana de contexto. Es decir, lo equivalente a un texto de 3.000 palabras. Hoy en día, modelos como los de Google Gemini llegan a 2 millones de tokens. Por lo que puedes cargar en el modelo literalmente El Señor de los Anillos, varios manuales técnicos y el código de nuestra web. Y lo mejor: podemos preguntarle por ello sin que pierda el hilo en ningún momento.
Temperatura
La temperatura es una calibración que mide cuánto de creativo puede ser un modelo, en detrimento de la precisión de sus datos. Es muy sencillo de entender:
- Una temperatura de 0.0 supone que el modelo SIEMPRE escogerá la palabra más probable. Por lo que es idóneo para código, matemáticas o extracción de datos. Si le preguntas dos veces lo mismo, nos responderá de la misma manera.
- Temperatura 0,8 – 1.0: El modelo comienza a tomar riesgos y elige palabras menos probables, pero interesantes. Algo que puede resultar muy útil en escritura creativa, poesía o una lluvia de ideas.
Ten en cuenta que, rebasar una temperatura de 1.5 supone un alto riesgo de que el modelo comience a decir incoherencias y a «balbucear» sin sentido alguno.
Tipos y ecosistemas de modelos
El mercado de la IA se ha dividido en dos grupos que llevan enfrentados prácticamente desde la existencia de los sistemas operativos. Por lo que has de entender cuál estás utilizando para saber qué puedes -y qué no- hacer con la tecnología.
Modelos cerrados o propietarios
Pertenecen a este tipo los modelos que pertenecen a una empresa. Prácticamente, son los modelos más conocidos del mundo, tales como GPT-5, Gemini o Claude. Sus ventajas están muy claras, y es que están extraordinariamente desarrollados y son los más inteligentes que podemos encontrar en el mundo. Cuentan con ventanas de contexto gigantes y capacidades de razonamiento superiores. Y eso se debe a que se ejecutan en superordenadores que valen millones de euros.
Sin embargo, no todo es oro lo que reluce. Tienes que tener en cuenta que no somos dueños de nada. Nuestros datos viajan a servidores de esa empresa. Pueden censurar tus respuestas si consideran que violan sus políticas y cada pregunta cuesta dinero, o bien una suscripción. En el caso del uso gratuito, siempre cuenta con límites. Son lo más parecido a una «caja negra». Sabemos lo que entra y lo que sale, pero no su funcionamiento.
Modelos abiertos (u «Open Weights»)
Pero no todo en el mundo de la IA ha de estar supeditado a un interés comercial superior. De hecho, existen soluciones muy potentes perfectas para usuarios de a pie, desarrolladores y empresas. Es aquí donde entran modelos como Llama 3, de Meta, Mistral, de Francia, o Qwen, de Alibaba.
A menudo, se les puede conocer incorrectamente como «Open Source». Algo a lo que estamos acostumbrados en otro tipo de software. Pero el término técnico correcto en este campo es «Open Weights». La empresa o los desarrolladores liberan estos «pesos», que son los modelos, para que los descarguemos y los utilicemos gratis en nuestro PC. Sin embargo, no lo libera todo: generalmente guardan el código de entrenamiento y los datos originales. Aun así, una vez descargado, el modelo es nuestro. Puedes desconectar internet y seguirá funcionando perfectamente. Y por supuesto: nadie puede ver qué preguntamos ni censurar respuestas.
Tal es el reconocimiento de este tipo de modelos que incluso OpenAI tuvo que ceder ante la presión del mercado y lanzar GPT-OSS (versiones de 20b y 120b). Una declaración, tal vez, de que el futuro puede pasar por un escenario híbrido.
Modelos Open Source y de nicho
También encontramos modelos realmente abiertos como el ejemplo de OLMo de Allen Institute. Aquí sí que se publica todo, incluidos su código fuente y datos de entrenamiento. Y en este apartado, son fundamentales para una investigación científica de garantías. En paralelo, también encontramos modelos de nicho. Se llaman así porque están creados específicamente para un campo especializado: medicina, leyes, programación… En términos de rendimiento, puede superar incluso a los modelos más caros si solo se enfoca en un área pequeña de especialización. Aun así, hablamos de modelos hasta 10 veces más pequeños que los comerciales. Por lo que puede decirse que son más eficientes en cuanto a su tamaño/rendimiento.
Cómo leer la «etiqueta» de un modelo de IA
A la hora de entrar en un repositorio, como Hugging Face, que es el equivalente al «GitHub de la IA», y buscamos un modelo, nos encontraremos con nomenclaturas extrañas que acompañan al nombre principal de un modelo. Así que vamos a aprender a leerlo median teun ejemplo real:
Llama-3-70b-Instruct-v1-GGUF-q4_k_m
Así que vamos a ver qué significa cada una de estas etiquetas para los diversos modelos que existen actualmente:
- Llama-3: en este caso nos encontramos la familia del modelo. Nos indica tanto la arquitectura base como el creador, que en este caso es Meta.
- 70b: como hemos mencionado antes, es su tamaño. Tiene 70 billones de parámetros. Nos dice inmediatamente si necesitamos un mejor o peor hardware. En el caso de estos 70b, necesitaremos una tarjeta gráfica muy potente (unos 48 GB de VRAM). O bien un Mac con mucha memoria unificada. En el caso de que encuentres un modelo «8b», seguramente puedas moverlo con un portátil gaming decente.
- Instruct: uno de los parámetros más iportantes. Con «Instruct» quiere decir que se ha entrenado especialmente para seguir instrucciones y conversar con nosotros, los humanos. En el caso de que quieras un asistente personal, SIEMPRE debes buscar esta etiqueta. En caso contrario, si le preguntamos cuál es la capital de Japón, podría respondernos con algo del tipo «¿y cuál es la de España?, porque puede creerse que está completando una lista de preguntas. No nos sirve para chatear.
- GGUF: el formato o tipo de archivo. En este caso, nos encontramos GGUF, pero existen de más tipos: GGUF es el estándar para ejecutarse en CPU o en Mac. Es el formato que utiliza, por ejemplo, programas como LM Studio, del que hablaremos ahora. EXL2/ GPTQ/ AWQ: si en vez de GGUF, ves cualquiera de estos, significa que estás ante un modelo optimizado exclusivamente para ejecutarse en tarjetas gráficas de NVIDIA a máxima velocidad. Safetensord es un formato «en bruto», por lo que suele requerir una conversión previa para que podamos usarlo en nuestro PC.
- q4_k_m: el número 4 nos dice que el modelo se ha comprimido a 4 bits, una calidad media. Es básicamente la cuantización. Lo que nos permite meter un modelo gigante en nuestro disco duro perdiendo la mínima inteligencia posible en el proceso, pero vamos a hablar de ello precisamente en el siguiente punto.
La compresión de un modelo de IA: entendiendo la «Cuantización»
En el caso de que hayas intentado descargar un modelo «State of the Art», como puede ser Llama 3 70B, te habrás fijado en una cuestión muy importante: su archivo original pesa más de 140 GB. El problema para la mayoría de los usuarios es que es imposible de ejecutar. Y no porque no se puedan instalar 140 GB, sino porque no existe ninguna tarjeta gráfica comercial que pueda moverlo. Ni siquiera una RTX 4090 que cuesta 2.000 euros. Porque no existe tanta VRAM en GPUs domésticas. Precisamente para traducir esas ingentes cantidades de computación a nuestros PCs de andar por casa existe la cuantización.
El «cerebro» de un modelo de IA guarda sus conocimientos utilizando muchos números decimales con el objetivo de ser ultra preciso. Un ejemplo puede ser «0,123456». A esto se le llama precisión FP16 (16 bits). La cuantización es el método que nos permite redondear dichos números para que ocupen menos espacio en nuestra memoria (en este caso, puede ser «0,12»). Sin embargo, esto conlleva una pregunta muy importante: ¿Pierde mucha capacidad de «pensamiento» la IA en el proceso? La respuesta es sencilla: curiosamente, no mucho.
Las investigaciones durante el año 2025 han demostrado que reducir un modelo de 16 bits a 4 bits (Q4) apenas afecta a su inteligencia en cuanto a tareas de chat, resumen o escritura creativa. Pero también hay aspectos importantes que hemos de conocer para no equivocarnos al elegir archivos.
- Q4_K_M: el parámetro que hemos visto en el apartado anterior. Es la configuración recomendada para el 90% de los usuarios. «Q4» son los bits, y «K_M» el método inteligente K-Quants que «comprime las neuronas menos importantes», pero mantiene las más importantes para el funcionamiento del modelo. Todo esto se traduce en un resultado muy básico: un peso un 70% más ligero que el original, pero manteniendo el 98% de su capacidad de razonamiento.
- Q2/ IQ2: Si bajamos a 2 bits para intentar meter un modelo gigantesco en un PC con hardware más limitado, seguramente nos vamos a encontrar inestabilidad por doquier. Aquí el recorte de «inteligencia» sí es notable (prácticamente una lobotomía). Lo normal es que el modelo comience a sufrir bucles, repetir frases o perder la coherencia lógica en problemas matemáticos.
- La caída en razonamiento. El estudio «Quantization Hurts Reasoning?» del año 2025 reveló que, aunque un modelo cuantizado escribe igual de bien, sí que sufre en las tareas más enfocadas a la lógica pura, como las matemáticas o la programación más avanzada. Por lo que si necesitas una IA que resuelva un problema de física, siempre deberías intentar utilizar la cuantización más alta que soporte tu hardware (normalmente Q6 o Q8 en un PC de casa).
El truco de la VRAM
Para saber fácilmente si podemos ejecutar un modelo en nuestro PC, olvídate por un momento de la memoria RAM de tu sistema (la de Windows). Lo que importa aquí es la VRAM de tu tarjeta gráfica. Y para ello, existe una regla general muy rápida: multiplicar los billones de parámetros por 0,7 GB.
- Llama 3 8B (Q4) es igual a 8 x 0,7 = 5.6 GB de VRAM. Por lo que cabe casi en cualquier tarjeta gráfica medianamente potente.
- Llama 3 70B (Q4) es igual a 70 x 0,7 = 49 GB de VRAM. Es decir, que necesitas hardware muy potente y especializado, que no vas a encontrar en un PC comercial.
El mundo de la ejecución de IA local: las distintas opciones
Ejecutar una IA en local puede ser todo un desafío para muchísimos PCs hoy en día. Básicamente, o tienes un PC de categoría industrial o te ves condenado a utilizar un modelo muy cuantizado, como hemos explicado en el apartado anterior. Esto no pasa cuando utilizamos ChatGPT o Gemini, donde cada palabra que escribimos viaja a un servidor ajeno a nuestro PC. Allí se procesa y se guarda para entrenar sus futuras versiones, aparte de para responder nuestras cuestiones.
Pero si queremos ejecutar un LLM en nuestro propio PC, también tenemos herramientas para ello: LM Studio y Ollama son los principales exponentes en este campo. Estas te permitirán desconectar el cable de internet y tu IA seguirá respondiendo. No depende de ningún servidor externo. Sin embargo, no es la única manera de utilizar nuestro «ChatGPT privado». De hecho, el mercado está polarizado entre 2 filosofías opuestas: la fuerza bruta y la memoria infinita. Vamos a explicar qué es.
El camino de NVIDIA
Si eres un gamer y dispones de un sistema operativo Windows o Linux con una buena GPU de NVIDIA, tu referencia absoluta es CUDA. De hecho, las tarjetas NVIDIA de la serie RTX 3000, 4000 y 5000 son las reinas de la velocidad. Su principal ventaja es que cuenta con una velocidad de respuesta instantánea. Un modelo de 8B de parámetros vuela y nos genera un texto más rápido de lo que lo podemos leer. Sin embargo, la memoria VRAM es muy cara (más aún desde que existe el fenómeno de la IA). Para que te hagas una idea, la RTX 4090 «solo» (reiteramos el «solo») tiene 24 GB de VRAM. Esto quiere decir que nos limita a modelos de hasta unos 30-35B de parámetros. Por lo que si quieres soportar un modelo de 70B, vas a necesitar comprar una segunda 4090 con su correspondiente precio. O desembolsar cantidades ingentes por gráficas profesionales inalcanzables para la mayoría de usuarios.
El camino de Apple
Apple también ha encontrado su propia ruta dorada con la IA. Los Mac Studio y MacBook Pro con chips M2/M3/M4 cuentan con una estructura llamada «Memoria Unificada» que es de lo más interesante. la RAM del sistema también es la memoria de vídeo del propio sistema. Por lo tanto, puedes hacerte con un Mac Studio que cuenta con 192 GB de memoria unificada. Lo que nos permite ejecutar modelos increíblemente grandes como Llama 3.1 405B (cuantizado) o DeepSeek 67B. Algo con lo que sueña cualquier tarjeta gráfica comercial doméstica. De hecho, es la única forma medianamente «accesible» de tener una IA del tipo GPT-4 en tu propio PC de manera local.
Pero también ten en cuenta que son más lentos. La memoria de Apple no es tan rápida como lo puede ser una GDDR6X de NVIDIA. Por lo que el texto se generará a una velocidad relativa a la de la velocidad de lectura humana. Nada de instantaneidad. Sin embargo, es perfecto para analistas, investigadores o desarrolladores que priorizan la «inteligencia» del modelo sobre la velocidad.
LM Studio y Ollama
Estas apps son la puerta de entrada perfecta para cualquier usuario que necesite una IA segura a nivel local de la manera más sencilla posible.
Por un lado, tenemos LM Studio. Esta app nos proporciona una interfaz visual pulida, muy parecida a ChatGPT, donde podemos buscar modelos disponibles en Hugging Face y descargarlos con un solo clic para chatear. De hecho, cuenta con herramientas para que configuremos por separado los parámetros que hemos especificado en este artículo: la memoria que utiliza, la temperatura, la carga sobre la GPU o la CPU…
Ollama es la referencia más extendida entre los desarrolladores. Cuenta con un modelo gráfico al más puro estilo LM Studio, pero también con su control por terminal. Permite que otras apps, como editores de código u Obsidian, entre otras, «hablen» con nuestra IA local de manera sencilla. Es cierto que esta opción puede ser menos sencilla a nivel visual y técnico, pero sin duda la más optimizada para integrar la IA dentro de nuestro trabajo diairo.


