

LM Studio es una aplicación de escritorio pensada para utilizar la inteligencia artificial generativa directamente en nuestro ordenador. Es decir, que el propósito principal es no enviar datos a la nube. Y la importancia de ello radica en que refuerza nuestra privacidad y el control sobre nuestra información.
Desde LM Studio, podemos descargar modelos listos para usar y conversar con ellos en una interfaz por chat. Lo que nos evita cualquier instalación complicada o comandos de terminal. Además, hemos de saber que funciona tanto en Windows como macOS y Linux con requisitos muy razonables si miramos los equipos actuales.
Es decir, que en términos sencillos actúa como un centro de mando para ejecutar modelos locales: se elige un modelo, se carga y se empieza a preguntar o crear textos, resúmenes, código, ideas…
Además, ofrece un servidor local compatible con la API de OpenAI para integrarlo con aplicaciones y editores. De modo que las tareas se automatizan manteniendo todo en local. Por ello, vamos a explicar a fondo qué es LM Studio, cómo instalarlo y su funcionamiento y configuración para que puedas comenzar a sacarle partido desde el día 1.
Requisitos de LM Studio
Hemos de tener en cuenta que LM Studio es compatible con macOS, Windows y Linux, por lo que vamos a desgranar los requisitos para cada uno de los sistemas operativos.
Para instalarlo en macOS, necesitaremos:
- Procesador Apple Silicon M1, M2, M3 y M4. Los Mac Intel no están recomendados para LM Studio actual.
- El sistema deberá ser macOS 13.4 o superior.
- Memoria y espacio. Necesitaremos 16 GB de RAM para un funcionamiento estable y reservar 10-30 GB de SSD, aunque este almacenamiento variará dependiendo de los modelos que queramos instalar.
- No requiere GPU dedicada.
En el caso de Windows, deberemos cumplir con:
- CPU de 64 bits con soporte AVX2.
- RAM: 16 GB recomendadas para modelos de 7-8B. Aunque con 8 GB se puede empezar con modelos pequeños de 3-4B y contextos cortos.
- La GPU no es obligatoria, pero recomendable si se quiere acelerar.
- En cuanto al almacenamiento, cada modelo ocupa de 2 a algo más de 20 GB según el tamaño y la cantidad. Así que deberemos reservar en el disco duro una media mínima de unos 20 GB si queremos optar por más de un modelo.
Por último, en el caso del sistema operativo open source de Linux:
- Distribución: paquetes en AppImage para x64 (por ejemplo, Ubuntu 20.04 o superior). En caso de que tu equipo no disponga de AVX2, la experiencia puede ser más limitada.
- En cuanto a RAM y espacio: igual que Windows. 16 GB de RAM para modelos medios y una media mínima de 20 GB de en SSD para alojar varios modelos.
- En algunas distros puede ser necesario marcar el AppImage como ejecutable y permitir integración.
Descarga e instalación de LM Studio
Para descargar el instalador oficial para Windows, macOS o Linux, solo deberemos acudir a su web oficial, dentro del selector de descargas para los distintos sistemas operativos. En nuestro caso, vamos a descargar la última versión disponible para Windows, con un peso de 516 MB.
Se te descargará un archivo «.exe» que deberás ejecutar para su total instalación. Cuando se abra la ventana del instalador, nos dará a elegir si instalar el software para todos los usuarios del PC o solo para nosotros, por lo que deberemos escoger nuestra propia opción. Por defecto viene en «solo para mí». Luego elige la carpeta de destino donde se ubicará LM Studio, donde se nos requerirá 1.7 GB de espacio para ello. Una vez la tengamos, solo deberemos pulsar sobre «Instalar». Al finalizar, mantén activado el tic de «Ejecutar LM Studio» y pulsa sobre «Terminar».
Ahora, por fin, dispondremos del programa en nuestro PC. Por lo que, nada más ejecutarlo, veremos su interfaz principal abrirse a pantalla completa:
Primeros pasos en LM Studio
Por defecto, LM Studio se descarga e instala con el inglés como idioma predeterminado. Sin embargo, podemos cambiarlo en cualquier momento de manera muy sencilla. Tan solo deberemos irnos a la esquina inferior derecha, donde encontraremos este símbolo de engranaje, para pulsar sobre él:
Ante nosotros se nos desplegará un panel de opciones muy bien estructurado entre un menú central y columnas laterales. Pero, en esta ocasión, no deberemos tocar nada. Tan solo hemos de scrollear por el panel central hacia abajo. Al hacerlo, inmediatamente veremos aparecer la opción de «Idioma»:
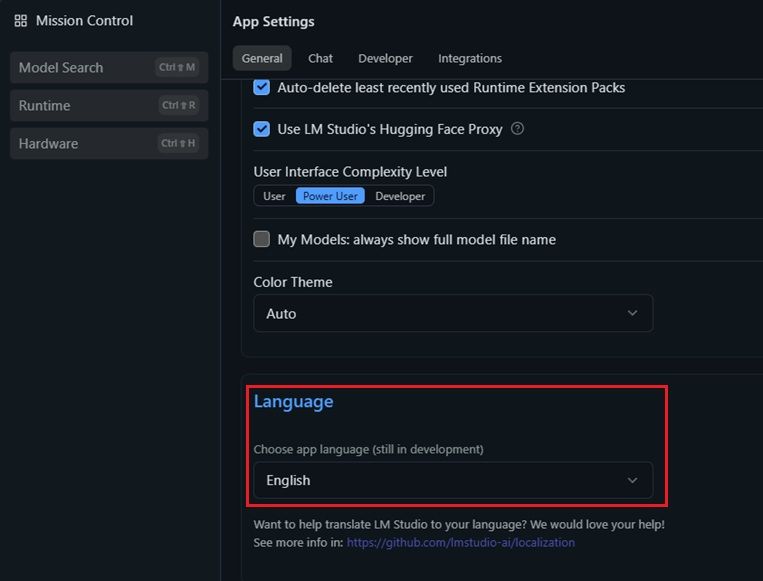
Solo debemos pulsar sobre el panel selector y seleccionar el idioma «Español (Beta)» para poder trabajar en nuestra propia lengua. Ahora que está el idioma ajustado, vamos a analizar la estructura principal del programa.
Si cerramos la ventana de opciones sin pulsar nada, llegaremos de nuevo a la pantalla principal que hemos visto al principio. Pero si nos fijamos bien en la parte izquierda, encontraremos 4 iconos ordenados a modo de columna con las distintas áreas de trabajo del programa:
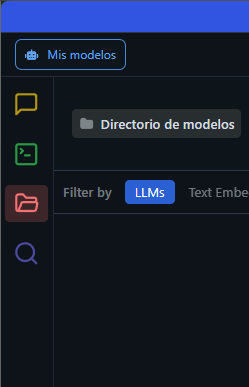
Cada uno de estos iconos de diferentes colores representa una sección diferente donde llevar a cabo distintas tareas en LM Studio:
- El icono del mensaje amarillo se corresponde con la sección de «Chats», que podemos abrir una vez hayamos instalado el modelo de lenguaje, tal y como explicaremos en el artículo.
- La ventana verde, con el nombre de «Desarrollador», nos permite activar un servidor local compatible con la API de OpenAI, revisar el endpoint y usarlo con apps externas.
- En la carpeta roja, bajo el nombre de «Mis modelos», encontraremos los modelos descargados por el programa. Hace las veces de «almacén» o inventario de todos los modelos descargados.
- La lupa morada, bajo el nombre de «Descubrir», se encarga de buscar los distintos modelos de IA para que podamos descargarlo y utilizarlos a nivel local. Así que es hacia donde nos dirigimos en la siguiente sección en nuestro camino a utilizar LM Studio con nuestra propia IA.
Accede a los modelos descargables de LM Studio
Dentro de la sección bajo el icono de la lupa morada (Descubrir), podremos encontrar los modelos con que vamos a trabajar en este programa. Es decir, nos encontraremos directamente con esta interfaz:
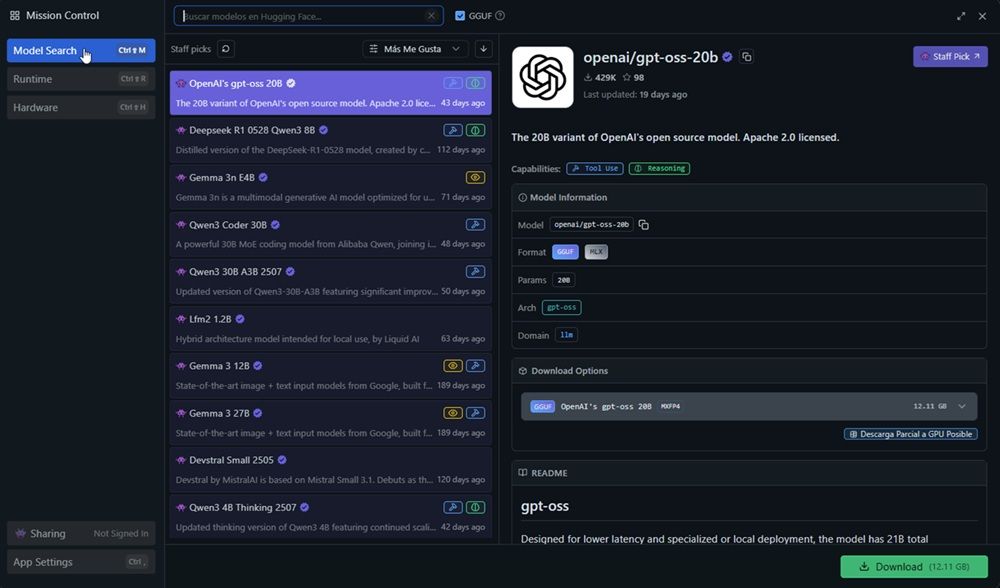
Como puedes ver, encontramos un listado de modelos abiertos de IA. Los cuales podemos filtrar u ordenar por «me gusta», «más descargas» o «actualizados». Aunque vamos a analizar los modelos más destacados con que podemos hacernos, disponemos en general de modelos de Qwen3, Lfm2, Ernie 4.5, Gemma 3n, Mistral, DeepSeek, Phi 4, Granite, Gemma 2 o Codestral. Sin embargo, basándonos en su optimización, hemos de mencionar los modelos mejor desarrollador para descargar:
OpenAI gpt-oss 20B
Este modelo abierto de los creadores de ChatGPT posee una licencia Aparche 2.0, y está orientado a instrucciones y razonamiento con un esfuerzo configurable. Es decir, que estamos ante la alternativa local oficial de ChatGPT. Pensada para ejecutarse en GGUF/MLX, dependiendo del equipo.
DeepSeek R1 Distill Qwen 7B
Nos encontramos ante una destilación del modelo de razonamiento de DeepSeek sobre Qwen 7B. En él, encontramos un buen equilibrio entre la potencia y los requisitos necesarios y admite cuantizaciones Q4-Q6 junto a contexto largo. Un modelo ideal para empezar con 16 GB de RAM.
Gemma 3n E4B
Si gpt-oss era la alternativa abierta y local de ChatGPT, Gemma 3 lo es de Gemini. Tiene builds GGUF listas para usar en LM Studio. Es un modelo de IA generativo multimodal que además está optimizado para cualquier dispositivo cotidiano, como puede ser nuestro PC, teléfonos, tablets o portátiles. Por el momento, admite una longitud de contexto de 32.000 tokens.
Qwen 3B y 4B Thinking
Qwen es una familia de modelos desarrollada por la empresa Alibaba que destaca por ofrecer varias versiones «Thinking». La más optimizada en LM Studio es 3B 4B Thinking. Estas variantes están específicamente diseñadas para funcionar en ordenadores con recursos menos potentes, y aprovechar de ese modo sus capacidades de IA local. Su contexto más habitual ronda los 8.000 tokens, más que suficiente para chats largos y generación de texto continuo. Están especialmente indicados para aquellos que buscan respuestas elaboradas por su equilibrio entre velocidad y consumo de memoria.
Magistral Small 2509
Uno de los modelos más ligeros basados en Mistral AI, optimizado para una buena comprensión de instrucciones y razonamiento general en dispositivos de bajo consumo. Esta versión «small» ronda los 2.5 billones de parámetros, lo que se traduce en rápida velocidad y baja exigencia de RAM. Aun así, es funcional solo a partir de los 8 GB de RAM. Se orienta a tareas como redacción, resúmenes y asistencia técnica.
Mistral 7B
El buque insignia de la startup francesa Mistral AI, conocido por su buen desempeño en español y acierto con tareas de lógica y matemáticos. Se encuentra bien documentado y optimizado en GGUF para que funcione a la perfección en LM Studio y otras apps locales. Su ventana de contexto cuenta con hasta 32.000 tokens en sus últimas versiones. Capacidad más que suficiente para dar continuidad a chats extensos y comprensión de textos largos sin consumir tanta memoria como modelos de más tamaño. Es la alternativa local perfecta para aquellos interesados en matemáticas y cuestiones de lógica.
Phi 4
Tal vez te hayas cruzado alguna vez con Phi 4, el modelo compacto de Microsoft. Está enfocado en gnerar un lenguaje natural preciso y respuestas lo más concisas posibles. Ronda los 1,7 billones de parámetros. Lo que significa que ocupa poco espacio y se puede ejecutar en casi cualquier ordenador actual. Sin embargo, su mayor ventaja es que está entrenado en procesar instrucciones y QA breves. Lo que lo convierte en una opción ligera para tareas como diálogos rápidos, ayuda técnica o generación de textos cortos. Es decir, ideal si se busca sencillez y un bajo consumo de recursos.
Pasos para descargar un modelo
Una vez que te hayas decidido por un modelo específico de la lista, solo deberás seleccionarlo. Por ejemplo, en la imagen de arriba, puedes ver que está seleccionado la alternativa de OpenAI. Por lo que se nos abrirá una ficha con los datos de dicho modelo. Es el momento de fijarnos en la parte derecha de dicha ficha, donde encontraremos esta información:
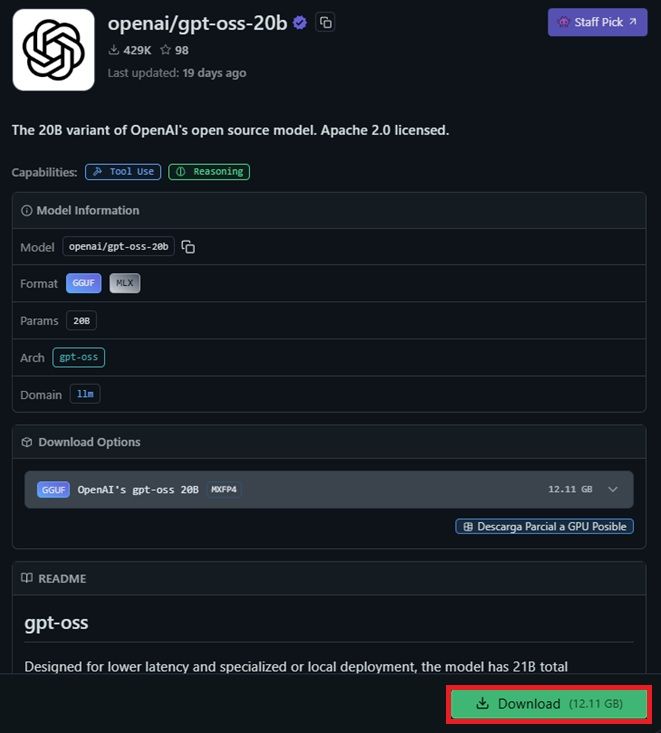
Abajo a la derecha de la ficha encontrarás un botón verde con el nombre de «Download» (Descargar) junto al peso en GB del propio modelo. En este caso, nos encontramos ante 12.11 GB de descarga. Cuando pulsemos sobre dicho botón, se te abrirá un gestor de descarga del propio LM Studio donde podrás ver en tiempo real el progreso y la velocidad de descarga del modelo. Por lo que solo tendrás que esperar hasta que se haya completado. Será en el siguiente punto donde comenzaremos a utilizar dicho modelo.
Configurar el modelo descargado
Una vez que hemos pulsado sobre «Download», tan solo deberemos esperar a que dicho modelo se descargue con normalidad. Una vez que se haya descargado con éxito, deberemos acudir a la columna de la izquierda y pulsar sobre el icono amarillo de la conversación con el nombre de «Chats». Cuando se expanda la sección, deberemos acudir a la pestaña central con el nombre de «Seleccione un modelo para cargar». Así lo podemos ver en la siguiente foto:
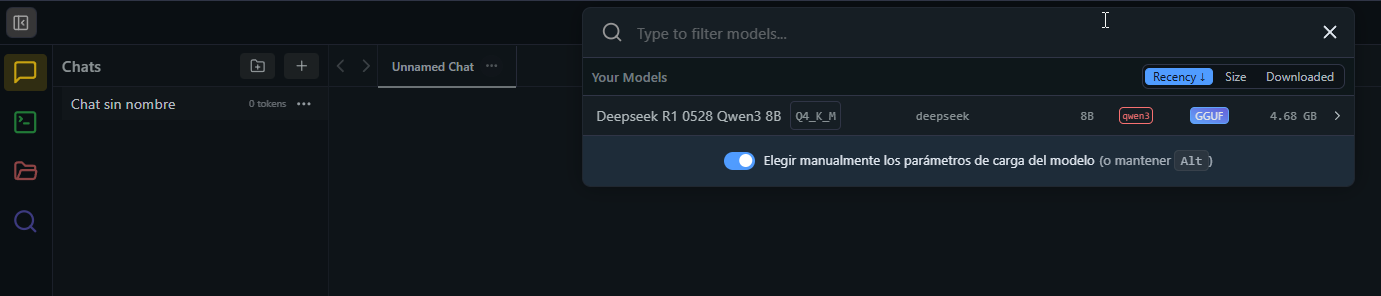
En este caso, nosotros hemos descargado DeepSeek R1 0528 Qwen 3 8B, de 4,68 GB de peso. Pulsa sobre su nombre y te aparecerá un panel con una configuración previa a la ejecución de dicho modelo:
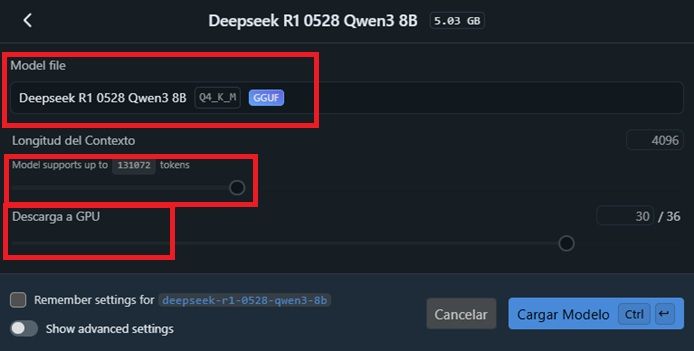
Principalmente, podremos ajustar tres opciones principales. Por un lado, encontraremos «Model file». Cuando pulsemos sobre ella, nos dejará escoger entre todos los modelos descargados (en caso de que tengamos más de uno). Por ahora, lo dejaremos tal y como está si solo disponemos de uno. A partir de ahí, deberemos configurar las siguientes opciones:
- Longitud del contexto: fija cuántos tokens puede «recordar» el modelo dentro de una conversación o tarea. Moverla hacia la derecha aumenta el tope de tokens, mientras que moverlo a la izquierda lo reduce. En este punto, debemos saber que el hecho de subir el contexto hace que se consuma más RAM/VRAM. Si falta memoria, aparecerán errores o cortes. Algo que se acentuará en equipos que dispongan con 8-12 GB de VRAM. Pero si nuestro PC nos lo permite basándonos en su capacidad, mejora la coherencia y permite funcionar con hilos de conversación más largos. Ten en cuenta que los contextos grandes implican más cómputo por token, lo que puede hacer que baje la tasa de tokens por segundo en PC más modestos.
- Descarga a GPU: la GPU procesa capas en paralelo y acelera la generación de contenido, especialmente en modelos 7B-20B y superiores. A cambio, hace un mayor uso de VRAM. Si se supera la VRAM disponible, sufrirás caídas de rendimiento, por lo que conviene ajustarlo progresivamente para no acercarte demasiado al límite.
En el caso de DeepSeek R1 0528 Qwen 3 8B, uno de los modelos más optimizados de todo LM Studio, lo ideal es que comencemos con un contexto de unos 8-16K de tokens. Este modelo acepta hasta 128K, pero la velocidad y calidad se mantiene mejor hasta un máximo de 16-32K en hardware estándar doméstico. Con respecto a la carga a GPU, podemos comenzar con el valor medio -20/36-. Puedes ir probando a subir la capacidad hasta que el rendimiento comience a decaer, y entonces retroceder.
Ahora que lo tienes todo configurado, solo tendrás que pulsar sobre «Cargar modelo» para comenzar a utilizarlo.
Comienza a utilizar tu chatbot local
Una vez que pulsemos sobre «Cargar modelo», se nos abrirá una ventana de chat donde podremos ingresar los diferentes prompts para que el propio chatbot nos responda. Es decir, una interfaz idéntica a lo que nos ofrece cualquier IA como Gemini, ChatGPT o DeepSeek.
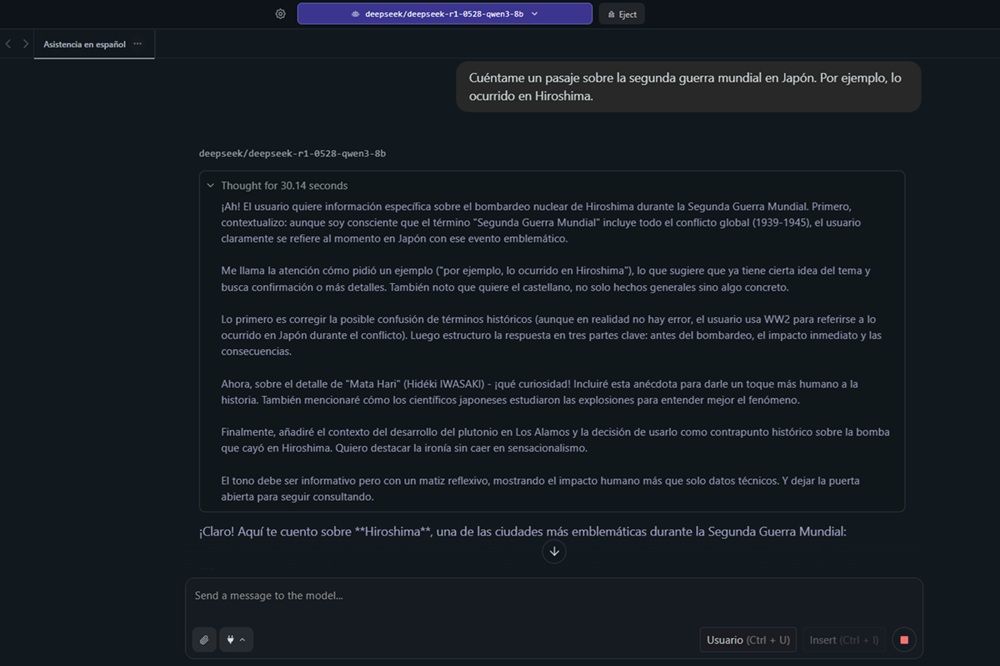
En este caso, se nos ocurrió preguntarle sobre conocimientos históricos con un tema sencillo, consultable en cualquier enciclopedia: «Cuéntame un pasaje sobre la segunda guerra mundial en Japón. Por ejemplo, lo ocurrido en Hiroshima».
El propio modelo fue notificándonos en todo momento su estructura de pensamiento y las acciones a realizar. Por ejemplo, sin informarle al respecto, fue capaz de interpretar datos como:
- El bombardeo nuclear ocurrido en dicha región en 1945.
- Su generación de estructura para la respuesta en 3 partes: antes del bombardeo, el impacto inmediato y las consecuencias.
- Decisión de incluir anécdotas relacionadas para aportar un toque humano a la respuesta (Mata Hari).
- Añadir contexto del desarrollo de la bomba nuclear que se llevó a cabo en Los Álamos y la decisión de utilizarla en Hiroshima sin caer en sensacionalismos.
- Por último, decide el tono que ha de aplicar: informativo pero con un matiz reflexivo, mostrando el impacto humano.
Esta estructuración de «pensamiento» llevó un total de 30,14 segundos de tiempo antes de responder. Tras ello, nos respondió con exactamente 544 palabras sobre el tema con la estructura y los datos aportados en su «thinking».
Al final del mensaje, aparecerán los tokens generados por segundo y la totalidad de tokens empleados. Bajo este mismo proceso, puedes escoger tu propia IA de entre las disponibles en LM Studio para obtener tu propia inteligencia artificial a nivel local. De esa manera, no dependerás de la conexión a internet para obtener un asistente inteligente que te acompañe a cualquier lugar.


